Python 并发编程方案异同
Python 并发编程方案异同
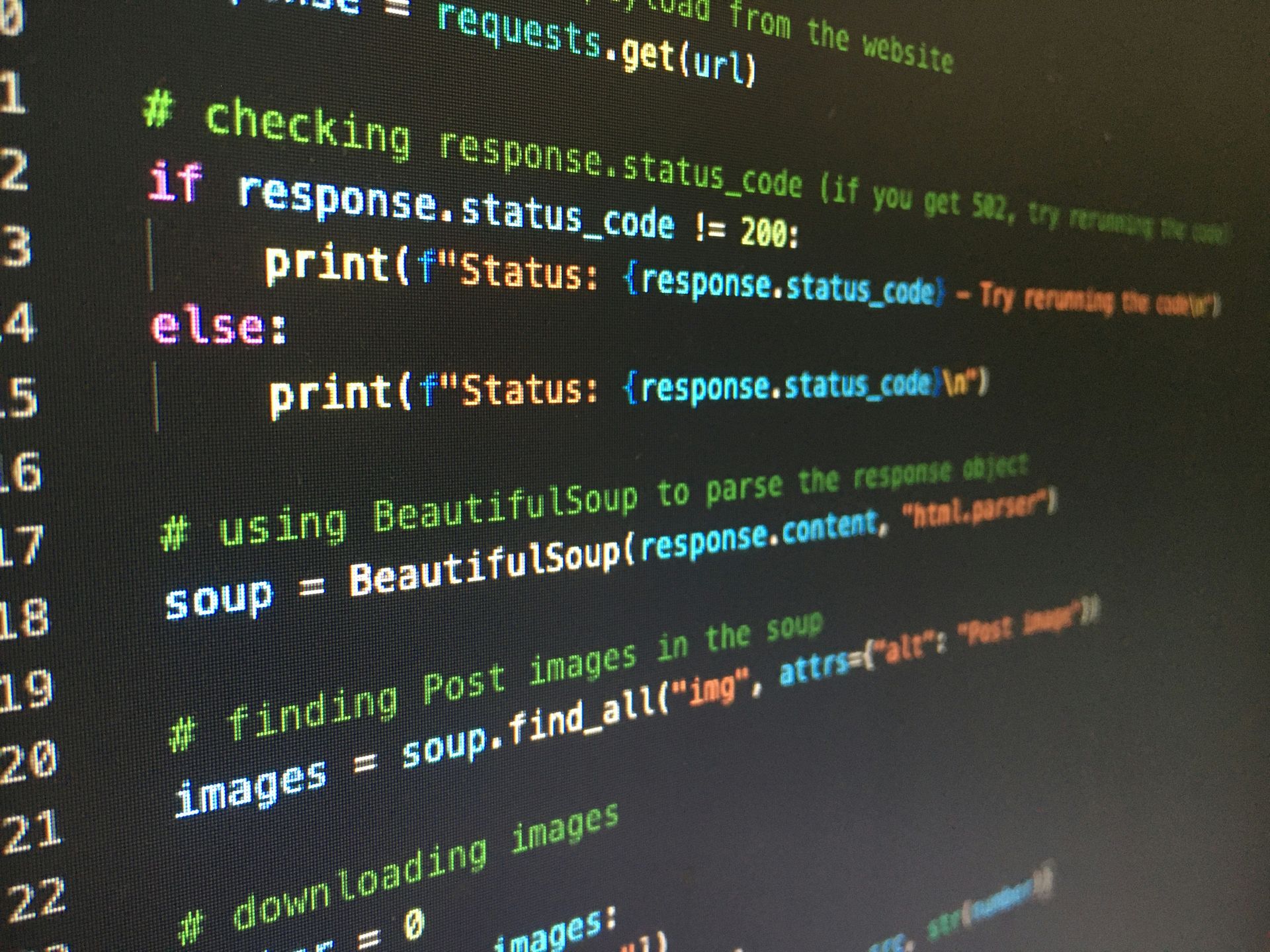
前言
博主最近用 Python 处理一些业务数据,每条数据都需要调用几个很慢的外部接口,初版实现是同步的,顺序的处理,但业务实际使用过程中,业务那边提出脚本运行缓慢,其中一条优化就是引入并发编程提高效率。
方向
Python 实现并发编程有如下常见方向:
- 协程:Python 3.5 以后的版本可用 asyncio 和 async/await 特性,可以实现单个线程的多任务并发
- 多线程:Python 提供了 threading 模块来支持多线程
- 多进程:Python 的 multiprocessing 模块可以创建进程
写一个模拟当时场景的 DEMO:
1 | |
运行结果为:
1 | |
协程方案
asyncio 可用于编写单线程并发代码,asyncio 的事件循环是其并发模型的核心,它负责调度和执行任务,处理 I/O 等待,以及提供各种同步变量同步。
协程方案的局限性在于这是一个单线程模型,依赖事件循环做上下文的切换,所以一旦任务中存在占用 IO 较长且未经过 async/await 做协程处理,就可能拖慢整体效率。
1 | |
关键部分包括:
-
async def:定义一个协程函数。协程函数是可以使用await 语句的函数。 -
await asyncio.sleep(0.5):这是一个异步的 sleep 调用。它会将控制权交还给事件循环,允许其他任务在等待期间运行。 -
asyncio.gather(*tasks):这个函数接收一系列的协程对象,然后并发地运行它们。当所有的协程都完成时,它返回一个结果列表。 -
asyncio.run(main()):这是运行协程的主函数。它创建一个事件循环,然后运行传入的协程。当协程完成时,它关闭事件循环并返回结果。
但是我们运行代码后会发现总执行时间依旧是 5s,这是因为 time.sleep 会让整个 Python 解释器(包括事件循环)都会被阻塞,无法执行其他任务
1 | |
这里只是模拟任务,time.sleep 更能模拟真实场景下的 IO 和计算资源占用,如果现实场景中需要在协程函数中使用 sleep,可以使用
asyncio.sleep(0.5),文件操作可以用 asyncio 包中的相关函数优化协程执行速度。
如果把上面的 time.sleep() 改为 asyncio.sleep(),执行日志如下:
1 | |
多线程方案
threading 可以让每个任务都在自己的线程中运行,这样可以实现并发执行,但由于 GIL(全局解释器锁)的存在,Python 的多线程并不能实现真正的并行计算。
GIL,全称为全局解释器锁(Global Interpreter Lock),是 Python 中的一个机制,用于确保同一时间只有一个线程可以执行 Python 字节码。这个锁主要是因为 CPython 解释器中的内存管理并不是线程安全的,所以引入 GIL 可以避免多线程同时操作 Python 对象引起的内存管理问题。
在 GIL 的影响下,同一个进程内的多个线程只能串行而不能并行。这意味着在任何时间点都只能有一个线程处于执行状态,但密集计算领域可能导致程序效率降低。
1 | |
执行结果如下:
1 | |
多进程方案
由于 GIL(全局解释器锁)的存在,Python 的多线程并不能有效利用多核优势,但多进程可以。
相比多线程,多进程的优缺点也很明显
优点:
- 并行处理:多进程可以利用多核 CPU 的优势,实现真正的并行计算。
- 独立性:每个进程有自己的内存空间,互不影响。如果一个进程崩溃,不会影响其他进程。
缺点:
- 开销大:创建进程的开销比创建线程大,尤其是在大量并发的情况下。
- 通信复杂:进程间的通信比线程间的通信复杂,需要使用特殊的 IPC(Inter-Process Communication)机制。
with Pool() as p 是创建进程池的代码,如果 with Pool(4) as p 代表进程池中最多存在 4 个进程
如果是 CPU 密集型任务,进程池的数量建议设为 CPU 核数,以及考虑内存限制、资源竞争等影响综合而定
1 | |
执行结果如下,可以看出由于创建进程成本比线程高,所以整体执行时间相比速度较慢
1 | |
总结
本文介绍了 Python 中实现并发编程的三种主要方法:协程、多线程和多进程。在实际应用中,需要根据业务需求和系统环境选择最合适的并发编程模式。希望这篇文章能帮助你理解 Python 的并发编程,在实际工作中提高代码的执行效率。