深度学习的数学原理-复杂函数求导的链式传递及多变量近似公式
前言
前文中对导数、偏导数已经有了概念并能进行简单计算,本篇主要介绍单变量和多变量的复合函数如何求导,以及近似公式的计算
正文
复杂函数求导
如果一个函数比较复杂,无论是用公式也好,还是用导数的定义强算也好,都比较麻烦,于是书中又介绍了关于复合函数的快速求导方法(高中数学知识),以及扩展了多变量复合函数的链式法则。
神经网络中的复合函数
这里又祭出那个十分熟悉的公式 
w1, w2, …, wn为各输入对应的权重,b为神经单元的偏置。输出函数是如下的x1, x2, …, xn的一次函数f和激活函数a的复合函数。
可以把这个函数看为两个函数的复合函数 
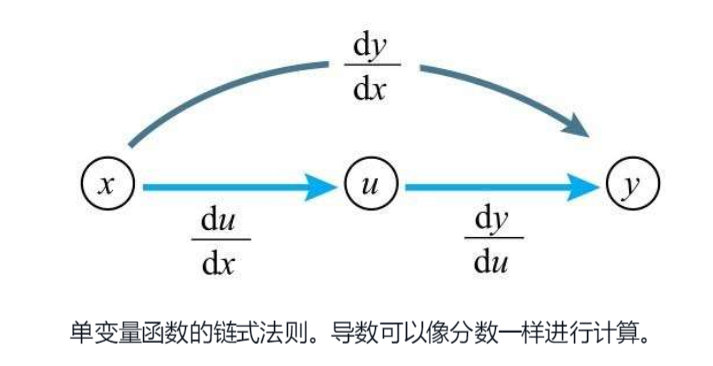
单变量复合函数链式法则
当已知 y = f(u) u = g(x),其导数可以依照下方所示的公式进行计算  仅看公式可能看不太明白,可以看一下书中的例题,例题中的符号有点难打,就直接贴图了。
仅看公式可能看不太明白,可以看一下书中的例题,例题中的符号有点难打,就直接贴图了。 
多变量函数链式法则
多变量函数的偏导数求导,也有一个链式法则。 比如变量z为u、v的函数,如果u、v分别为x、y的函数,则z为x、y的函数,z关于x求导时,先对u、v求导,然后与z的相应导数相乘,最后将乘积加起来。 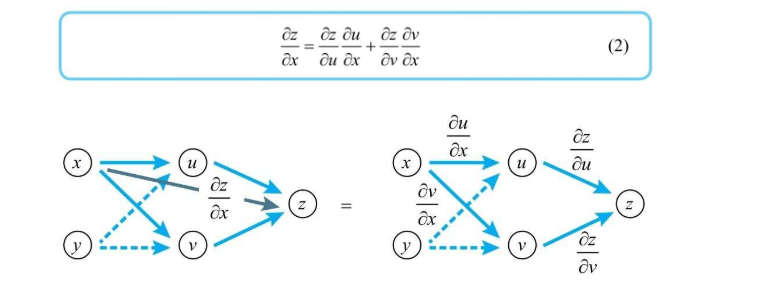
函数的近似公式
个人看下来,觉着作用是减少计算机计算量,书中强调这是梯度下降法的基础;
单变量函数的近似公式
根据导数公式,Δx->0 的时候,解出来的式子就是其一阶导数,如果Δ的值很小,那么下面的式子是成立的 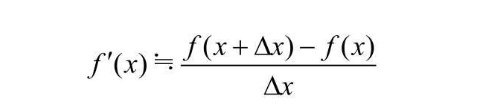 此时,将 f(x+Δx) 转换出来,就成了下面这个样子,这个式子就叫做单变量函数的近似公式
此时,将 f(x+Δx) 转换出来,就成了下面这个样子,这个式子就叫做单变量函数的近似公式  那么这个式子有什么用处呢?通过一个栗子来看一下
那么这个式子有什么用处呢?通过一个栗子来看一下
当f(x)=ex时,求x=0附近的近似公式。
根据公式可以得到如下的结果: 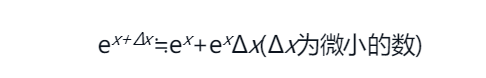 取 x = 0,再将Δx换成X,可得到
取 x = 0,再将Δx换成X,可得到 e^x = 1+x 在图形中有这样的含义,意思是 x=0 的时候 e^x 与 1+x 的结果相似: 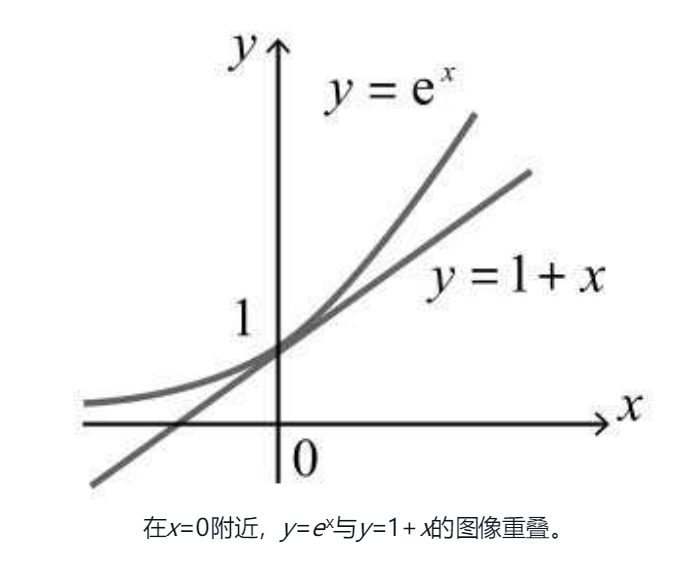
多变量函数的近似公式
这个公式可能比较好理解,但是不大好推导,x和y分别变化一个较小的数,其结果与 f(x, y) + x的偏导数_Δx + y的偏导数_Δy 近似相同  可以通过书中的一个例子来理解这个公式
可以通过书中的一个例子来理解这个公式
举个例子:当z=e^(x+y)时,求x=y=0附近的近似公式
按照公式,不难得出 f(x+Δx, y+Δy) = e^(x+y) + e^(x+y)*Δx + e^(x+y)*Δy = e^(x+y)*(1+Δx+Δy) 带入 x+y = 0,并将 Δx 换为 x ,Δy 换成 y 即可 1 + x + y 书中还提到了简化多变量函数近似公式的方法,首先有个 Δz 定义为x和y同时进行一个很小的变化与原函数值的差值 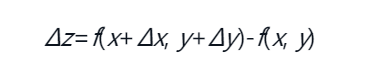 那么根据公式以及上述定义进行一下变换,可以得到
那么根据公式以及上述定义进行一下变换,可以得到  再对变量数量进行推广
再对变量数量进行推广  有没有很眼熟,是不是很像向量的内积,所以书中又提到了这个公式可以用向量内积的形式体现
有没有很眼熟,是不是很像向量的内积,所以书中又提到了这个公式可以用向量内积的形式体现 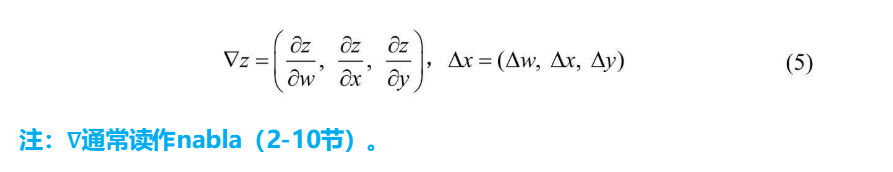
总结
主要介绍了单变量和多变量复合函数求导,还有单变量和多变量的近似公式及其向量内积表示,为日后梯度下降的学习打下基础。