深度学习的数学-向量与矩阵
前言
本篇主要学习下线代中向量与矩阵相关的知识,包括多维向量内积与机器学习中递推的关系,矩阵的基础概念和计算等;在书中也只提到与机器学习有关联的基础知识点,整体难度不算高;
正文
向量的定义
假设现在有两个点 A和B,那么 A->B 就是一个有位置(A的位置)有方向(A指向B的方向)有大小(AB线段的长度)的向量 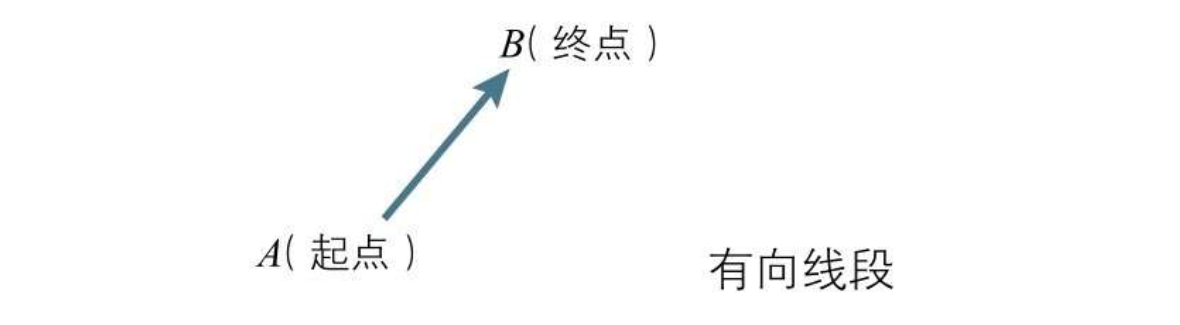 一个向量可以由如下三种方式表达
一个向量可以由如下三种方式表达 
坐标表示
如果我们建立一个直角坐标系,把A点移动到坐标原点,B点相对A点的位置不变,那么B点的坐标就可以看作是向量 A->B 的坐标表示 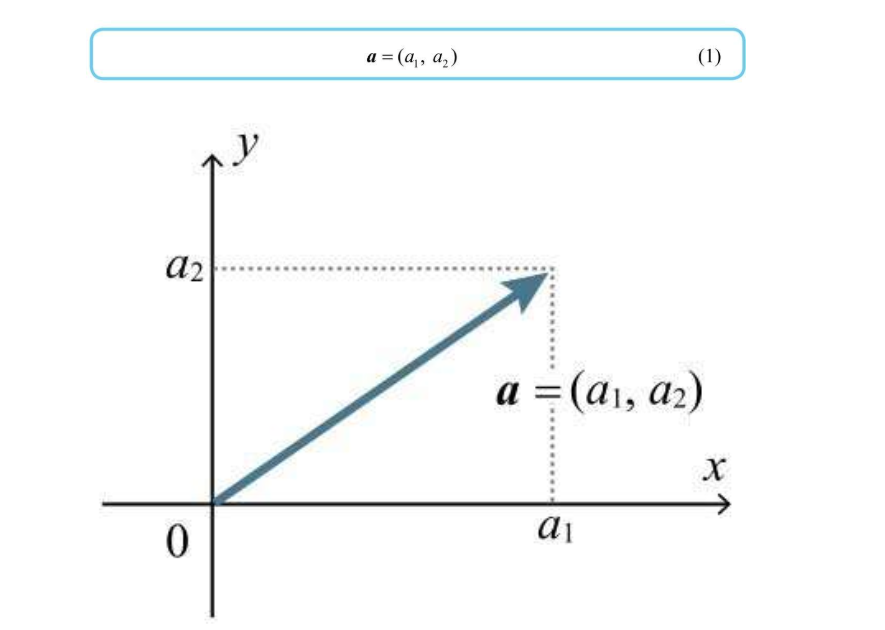 也可以把这个定义推广到三维甚至N维直角坐标系上,下图表示 A(1, 1, 1) 向量
也可以把这个定义推广到三维甚至N维直角坐标系上,下图表示 A(1, 1, 1) 向量 
向量的大小
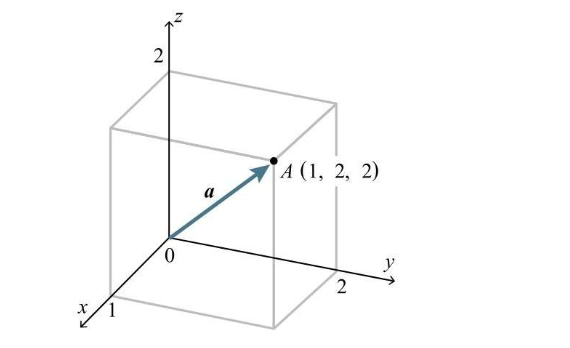
向量的大小用 a 表示,与绝对值符号相同 向量的大小即向量的长度,通过直角坐标系可以很方便的理解,比如 a = (3, 4),根据勾股定理,该向量的大小就是 5 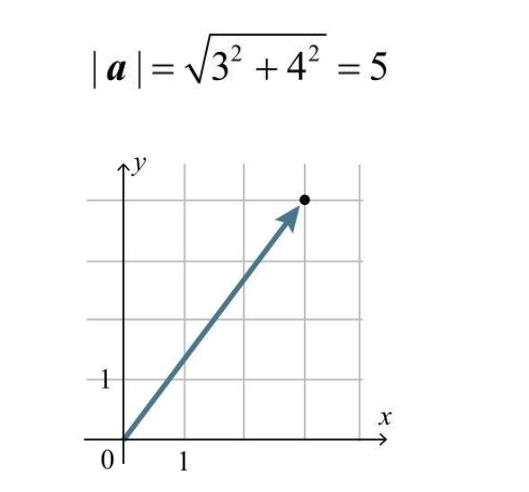 再推广到三维,a = (1, 2, 2),那么向量 a 的大小就是:
再推广到三维,a = (1, 2, 2),那么向量 a 的大小就是: 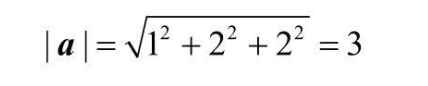
向量内积
向量的内积定义为两个向量的大小乘以向量夹角的 cos 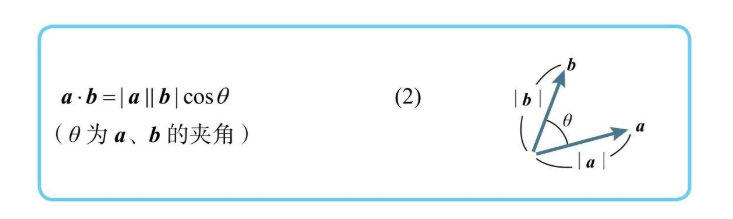 a和b,只要有一个为0,那么内积就是0 同理,这种解法也适用于三维向量
a和b,只要有一个为0,那么内积就是0 同理,这种解法也适用于三维向量 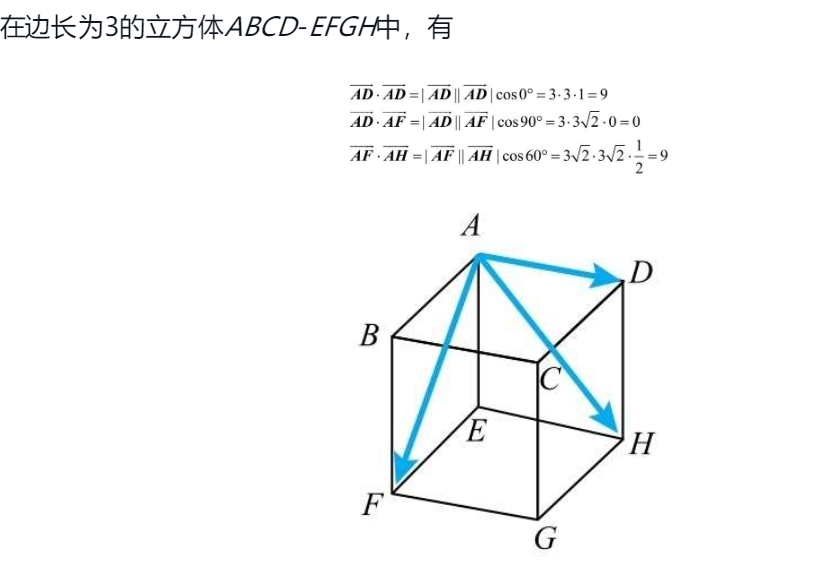
柯西不等式
因为任意的θ都会另 -1 < cos(θ) < 1,所以很容易推出下面的不等式 
 结合这个不等式,可以得到如下三种情况
结合这个不等式,可以得到如下三种情况 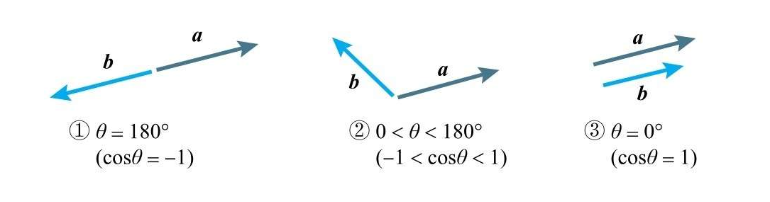
- 两个向量方向相反时,内积最小
- 两个向量方向相同是,内积最大
- 两个向量方向夹脚在 0 ~ 180° 时,内积大小会从最大到最小
书中特意提到,第一条性质(两个向量方向相反时,内积最小) 是日后梯度下降法的基本原理 
内积的坐标表示
还是首先以二维直角坐标系为例,内积可以以坐标的形式进行计算 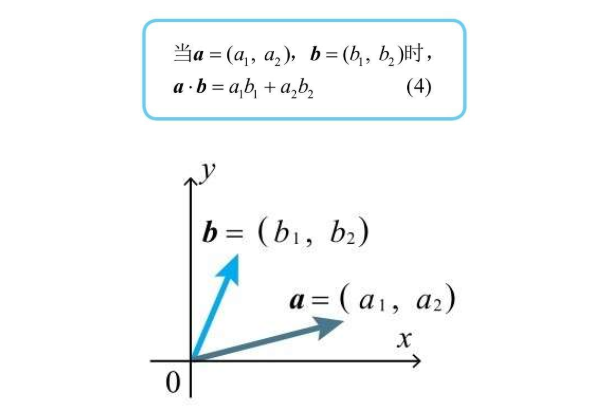 三维向量一样有这样的性质
三维向量一样有这样的性质 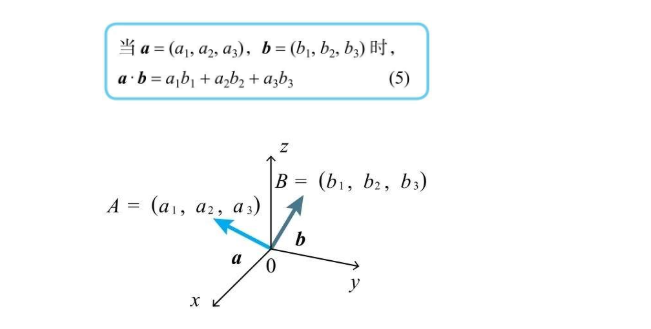
多维向量一般化(重点)

关于推导,我也尝试用我撇脚的数学推算过,算了一两页纸发现越算越复杂,推不出来,找了个别人的推导过程,有兴趣的可以研究下 https://blog.csdn.net/zhangyingjie09/article/details/88375120
看到这个向量内积公式,有没有想到之前提到的神经单元的加权输入: 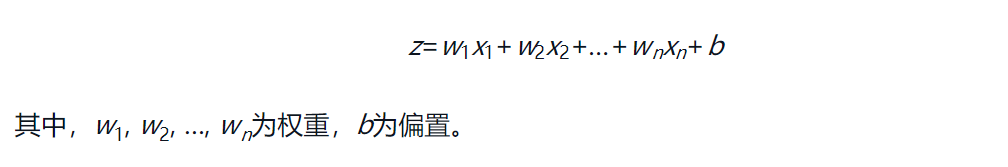 就可以表现为两个向量的内积加上偏置,向量 w = (w1, w2, w3, w4, …),x = (x1, x2, x3, x4, …),即:
就可以表现为两个向量的内积加上偏置,向量 w = (w1, w2, w3, w4, …),x = (x1, x2, x3, x4, …),即: 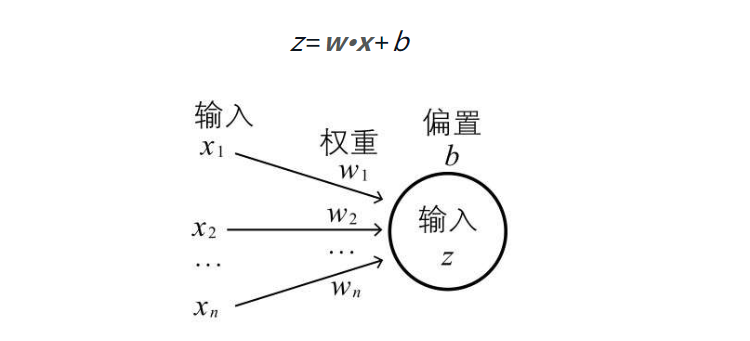
矩阵的定义
矩阵是数的阵列,横排为行,竖排为列,行数与列数相同称为方阵(类比正方形) 以及如下图X,Y所示的 行向量和列向量 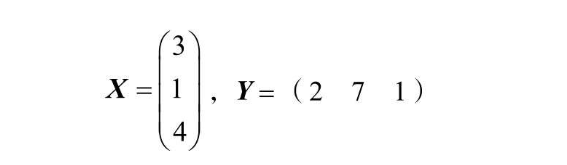 可以定义一个 m行n列的向量,第 i 行 j 列的元素用 aij 表示,
可以定义一个 m行n列的向量,第 i 行 j 列的元素用 aij 表示, 
单位矩阵
单位矩阵是一个特殊的矩阵,矩阵的斜对角线元素(aii)都是1,其他元素都是0 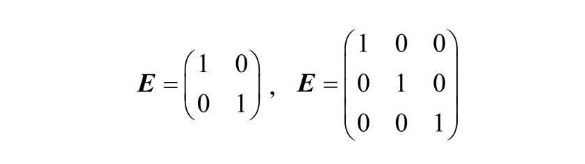
矩阵的运算
矩阵比较、和差常数积
A和B相等的含义是两个矩阵对应的元素包括行数列数完全相等 两个矩阵的和、差、常数倍都符合四则运算,和与差都是相同位置的元素直接进行加减,常数倍的乘法直接乘到对应的元素中去,如下: 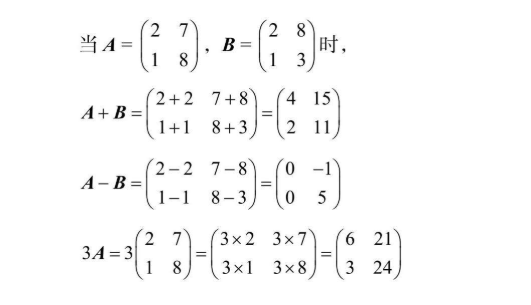
矩阵乘积(重点)
把向量A的i行看作行向量,向量B的j列看作列向量,其内积作为结果的 i行j列 的元素 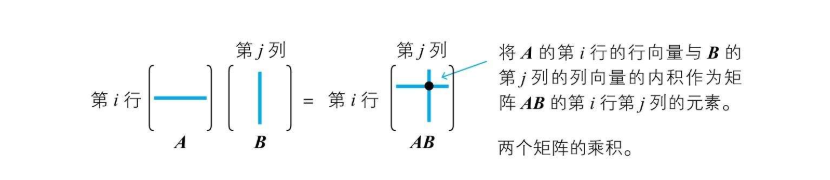 比如,两个向量乘积计算过程如下:
比如,两个向量乘积计算过程如下: 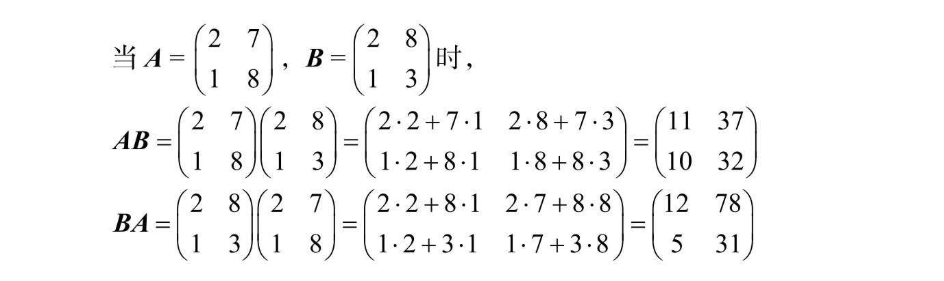
哈达玛积
Hadamard积适用于两个相同形状的矩阵,符号的含义是相同行数相同列数的数相乘,作为新矩阵对应函数和列数的值 下图表现了哈达玛积的计算过程,很直观 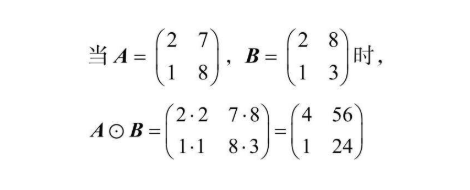
转置矩阵
转置矩阵是将矩阵A的i行j列的元素转换为新矩阵的j行i列,转置矩阵在原矩阵左上角加上一个小t表示 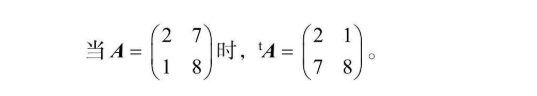
总结
本片博客主要介绍向量和矩阵的基础知识,其中多维向量内积与神经单元加权输入的关系(w = (w1, w2, w3, w4, …),b = (x1, x2, x3, x4, …),则 z = w*x + b)以及矩阵的乘积计算(i行j列 = A的i行向量与B的j列向量内积)是重点。