数据库索引总结
写在前面
此文部分文字图片来自公众号『架构师之路』,“数据库索引,到底是什么做的?”读了感觉很有帮助,特此记录,原文链接:https://mp.weixin.qq.com/s/larV76LMe_JXb7dz-LvNTg
数据库为什么需要设计索引?
举一个通俗的例子,比如我们想在字典上查“赟”这个字的读音,那么我们先把“赟”这个字拆解出偏旁部首,然后根据字典的目录查到这个字位于字典的666页,然后我们快速的翻到666页找到这个字读yun(一声),这里的目录就相当于索引,可以帮助我们快速找到某个字对应在字典中的页数 类比传统的关系数据库,其通过二维表描述一个实体,我们经常通过列的筛选条件去找到对应的行,比如有一张规模为1000W用户数据表,需要查找年龄大于22 的所有用户。
1 | |
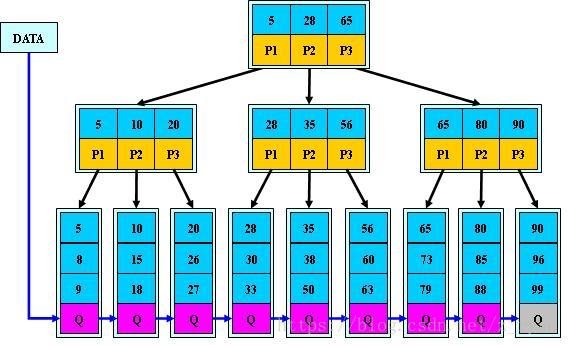
如果没有索引一条一条查,得查1000W次(全表扫描),但是如果我们有 age 字段的有序目录,就可以很快的根据目录找到对应的用户列了。
索引结构为什么是树形的?
学过数据结构的我们应该知道,加速查找常见的数据结构有两类: 1) 哈希,如HashMap,查询/插入/修改/删除的平均时间复杂度都是O(1) 2) 树,如平衡二叉树,查询/插入/修改/删除的平均时间复杂度都是O(lg(n)) 注意:MYSQL 的 innodb 引擎不支持 HASH 索引 HASH索引适合单行查找(不涉及范围),比如登录时的通过 name 找用户信息,会把 name 算一下HASH,并直接在索引的HASHMAP中找到对应的行即可。
1 | |
有序的树形索引,在处理排序、分组、比较时依旧能保持 O(log(N))的效率,而哈希型的索引则会退化为O(N)
1 | |
批注:数据表的删除会导致索引树的重建,影响删除效率
为什么使用B+索引
常见的树有如下几种:
1) 二叉搜索树
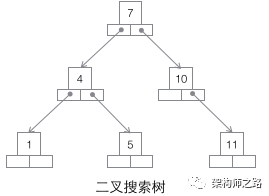
特性:
- 所有节点都存储一个数据
- 节点左侧的值比当前节点的值小,右侧比当前节点的值大
问题:
- 数据量大的时候,树的高度比较高,查询较慢
- 一个节点存储一个记录,导致一次查询可能会有很多次磁盘IO
2) B树
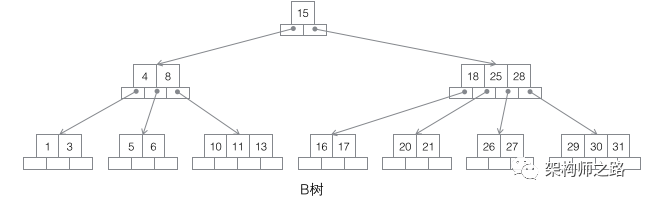
特性:
- M叉搜索,除根节点外,最靠左的的指针域中指向小于最靠左数据域的值,中间的指针域指向大于左侧数据域并小于右侧数据域的节点,右侧的指针域指向大于右侧数据域的节点
- 所有节点都存储数据
- 中序遍历可以获取所有的节点
3)B+树
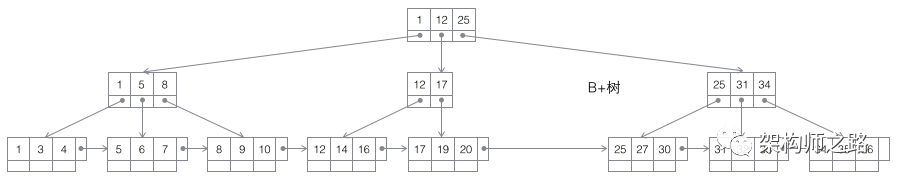
特性:
- 非叶子节点不存储数据,索引更小更适合内存存储,叶子节点存储的数据更紧密适合硬盘存储
- 范围查找更有优势,定位左右节点之后,中间的节点即为结果
- 非叶子节点不存储数据只存储索引,相同内存情况B+树能存更多索引
能够作为索引的结构的判断依据
1)存储器特性
内存读写比磁盘读写快很多
2) 磁盘预读取
每次读取磁盘是一页一页的读取,通常一页的数据量是4K
3) 局部性原理
尽量准许“数据读取集中”、“使用到一个数据,大概率会使用其附近数据”提高磁盘IO
总结
索引在实际数据库操作中,可能只是 INDEX(age) 之类的一句话,但是提速的效果确实很惊人的,一个高度为3的索引树即可索引5亿数据,不过索引也要用对地方,因为MYSQL 如果判断出用索引还不如全表搜索的话,就会退化为全表。